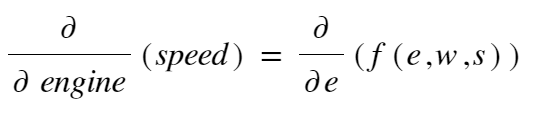(Jump to Machine Learning interview questions directly)

Ok so now you’ve reached the stage where you think you’ve a good grasp over the subject and now want to look up ahead on this road? Well this was my reason to first google ‘Machine Learning interview questions’. Maybe yours too to goole “facebook data scientist interview questions”, “amazon machine learning interview”, “machine learning quiz”, “interview questions for data scientist” bla bla and bla. One thing is for sure, if we’re googling this, it is most likely that we’re sort of in love with Machine Learning now. Haha, don’t know about you but I AM.
Enough of chitchat, let’s get down to business. Let’s get down to Machine Learning interview questions! I curated this list of sample interview answers by googling a lot! And with a lot, I mean A LOT. Plus, I also cross-checked the questions with some of the professionals working in this field, and trust me, I gained so much knowledge just by writing this article, and why not? Learning by asking questions is my favourite way of learning, but for that, you also need the art of asking questions (it’s a golden skill). I hope you also experience the same and get what you were looking for. (And do not worry, I’m not gonna answer the age old question : "Different types of Machine Learning!" EVERYBODY KNOWS THAT!)
To not go overboard with ‘Structural Representation’, I kept it simple and divided Machine Learning interview questions into 3 level of difficulties (had some fun with the names though):
- I’m just a noobie
- I’ve made 10 projects you silly
- I publish one research paper a day, dumbass.
Machine Learning interview questions
a. I’m just a noobie (Easy)
Q1. What are the different types of Machine Learning?
Haha …..just kidding!! Got you :p
Real Q1. How does Deep Learning differ from Machine Learning?
- It’s like asking how Potato is different from vegetables! Exactly, they aren’t different. Deep Learning is just a subset of Machine Learning,
- Deep Learning is nothing but the evolution of Machine Learning.
- Yes, I agree that a Machine learning model does get progressively better over time in whatever they are being trained on, but they still need some guidance. When the ML model starts giving wrong predictions (high error), an engineer has to step in to tinker with some parameters to optimize the algorithm further, manually.
- Whereas, a Deep Learning algorithm is intelligent in its purest form. It fixes its error itself, i.e, it optimizes itself when it starts getting wrong predictions with no human intervention through its own Neural Network.
- Though, a Deep Learning model as to outperform an Machine Learning model requires a lot more training and a lot more Data. But if given the right ingredients, it can outperform Machine Learning models like crazyy!

For more detailed explanation, just go and read (after this though, promise?)
“Machine Learning Deep Learning - Comparison in 2020 (Updated!)”
“Machine Learning Deep Learning - Comparison in 2020 (Updated!)”
Q2. Which is more important to you– model accuracy, or model performance?
- First of all, model accuracy is just another “evaluation metric” among thousand others in model performance.
- Model accuracy is nothing but just the percentage of how many times your model was correct out of the total number of predictions.
- There are tons of other measures too, and which evaluation metric can depend on various measures like the type of problem, requirements, type of solutions etc.
- Lastly, as model accuracy is just another part of model performance, they are directly proportional (+ve correlation) anyways.
Classification and Regression are the two categories of Supervised Learning. The only difference between them is the type of question asked. Confused? Ok wait…
- Classification:
- As the name suggests, it CLASSIFies things.
- It basically is the discrete answer to anything. Male/Female, Buy/Don’t But, 0/1
- Understand it like this. ‘Will it rain today?’ → ‘Yes’; ‘Is he old?’ → ‘No’
- Regression:
- As the name suggests, it REGRESS….ok wait, this won’t work with Regression.
- It basically is the type of problem where the answers cannot be discrete but continuous. Age, Price
- Understand it like this. ‘How much will it rain today?’ → ‘2mm’; ‘How old is he?’ → ‘22’
Q4. What is the Training/Test split?
- The first thing we learn in Machine Learning is that age old good rule of thumb of splitting the dataset into 80% Training and 20% Testing sets. And as the legend says, it works ...most of the time.
- The thing is, it totally depends on our dataset volume. For example:
- Assume that we’ve a dataset with 1 million samples, according to the thumb rule, 20% of our dataset would be 2 freaking hundred thousand samples allocated for the test set. You know how dumb that move is? If we’ve such a huge dataset, we can easily go with allocating even just 1% of the dataset, which still is 10,000 samples (which sounds just about right) and the performance won’t be tempered, if anything, the model will perform better. And do you realize what this move did, changed the split to 99:1!
- Again, let’s assume that we’ve a small dataset with just 500 samples. In that case, we might have to allocate a little more than 20%, let’s say 30% of out dataset (150 samples) to test set, just so that the model evaluation is done properly. Now that makes it 70:30 split!
b. I’ve made 10 projects you silly (Medium)
Q5. What is a Confusion Matrix?
For that, we need to understand 4 different types of answers:
Ok so you’re in love. And you, hopeless lover, sends a love letter to your girl and asks your best friend, Trump, to go and find out the reply. He comes back and spits out:
- “Yeah Man, you got it!” (Positive answer)
Listening to this, you run to her and hug her….
- She hugs you back. No confusion. Trump was right. → True Positive
- She slaps you. Trump was wrong. → False Positive
- “Sorry buddy, we’ll find someone better for you don’t worry..” (Negative answer)
Listening to this, you run back to home and cry in your pillow…
- She kept waiting for you and cried when you didn’t come. Trump was wrong. → False Negative
- No confusion, everybody is clear. Trump was right. → True Negative
And THAT, is what a Confusion Matrix is made up of. It contains the counts of True Positive, True Negatives, False Positives, False Negatives.
(Sorry for the wierd analogy!)
 |
| Confusion Matrix |
This matrix is very useful in analyzing/evaluating the predictions and make further changes accordingly.
Q6. What’s the difference between Type I and Type II error?
This looks like WHAT THE HECK!? But trust me, it’s a lot easier than it sounds. Remember the False Positives and False Negatives we discussed earlier?
- TYPE I is just another name for False Positives, and
- TYPE II is just another name for False Negatives.
“A clever way to think about this is to think of Type I error as telling a man he is pregnant, while Type II error means you tell a pregnant woman she isn’t carrying a baby.”
Q7. What are Bias and Variance?
These twins are nothing but just another terms in the Machine Learning family. But do not overlook them, they’re really important.
- Bias is nothing but just the difference between the predicted output and the original label. High bias tells us that our lovely model isn’t accurate.
- Variance on the other half, is the difference between the predictions of the training sets. High variance shows fluctuations, i.e, that the model is not stable.
Q8. What do you understand by Precision and Recall?
Did you notice one thing? The Machine Learning family contains a lot of twins! Type I/Type II, Bias/Variance, Regression/Classification. And here it is again, yet another twin ...Precision and Recall.
- In the most simplest words put, Recall is nothing but simply the accuracy of our model, i.e, how many of the total answers are correct.
- Whereas Precision is simply the ratio of a number of events you can correctly recall, to the total number of events you can recall (mix of correct and wrong recalls).
 |
| Precision and Recall |
Q9. How is KNN different from K-means clustering?
KNN stands for K-Nearest Neighbours, whereas K-means clustering stands for, well, K-means clustering. The only thing common between them is the letter ‘K’, and that creates all the confusion.

Q10. What is the "Curse of Dimensionality?"
You lost your car keys. And you’ve to go home as soon as possible for the delicious dinner. White sauce pasta, beer, mozzarella cheese ‘n’ corn pizza and some chicken wings oh my god! Wait, let’s come back to Machine Learning interview questions now (*sigh), now you’ve to search for your keys asap or else the food will get cold. Now just imagine,
- I say,”Ok so this is a line, and you only have to search for the keys on this line only!” Won’t that be super-duper easy? Just keep following the line.
- I say,”Ok, so I think you must have lost it on the third floor.” Now the work got tedious. Right? You now have to search for the small keys in the whole floor.
- I say,”Ok, man you could’ve lost them anywhere in this building. Good luck!” Now you really need that ‘Good Luck’. Now the job really got warmed up cause you’ll have to search for the keys up and down the floors! You gotta turn on the Mr.Sherlock mode now.
Same happens in a model. The more the features, the more tougher it gets to minimize the loss. Though a good number of features are always recommended, but, too much of anything ain’t good either!
Q11. Explain the Bias-Variance Tradeoff.
- Predictive models have a tradeoff between bias (how well the model fits the data) and variance (how much the model changes based on changes in the inputs).
- Simpler models are stable (low variance) but they don't get close to the truth (high bias).
- More complex models are more prone to being overfit (high variance) but they are expressive enough to get close to the truth (low bias).
- The best model for a given problem usually lies somewhere in the middle.
- We need to aim for Low Bias + Low Variance to build a good model.
 |
| Bias-Variance Tradeoff |
c. I publish one research paper a day, you dumbass. (I’ve to tell?)
Q12. Is it better to have too many false positives or too many false negatives? Explain.
Well, there is no definitive answer for that. Actually, it depends on the question as well as on the domain for which we are brainstorming to solve the problem. If you’re using Machine Learning in the Healthcare/Medicine domain, then a false negative is super risky, since the report will not show any health problem when a person is actually unwell, and c’mon, who wants to play with people’s lives when it comes to it? It’s better to falsely accuse someone of a disease rather than risking it otherwise. Similarly, if Machine Learning is used in spam detection, then a false positive is very risky because the algorithm may classify an important email as spam. Just imagine a Google job offer email rotting in your spam for a year! (Felt it?)
Well, there is no definitive answer for that. Actually, it depends on the question as well as on the domain for which we are brainstorming to solve the problem. If you’re using Machine Learning in the Healthcare/Medicine domain, then a false negative is super risky, since the report will not show any health problem when a person is actually unwell, and c’mon, who wants to play with people’s lives when it comes to it? It’s better to falsely accuse someone of a disease rather than risking it otherwise. Similarly, if Machine Learning is used in spam detection, then a false positive is very risky because the algorithm may classify an important email as spam. Just imagine a Google job offer email rotting in your spam for a year! (Felt it?)
Q13.Explain Ensemble learning technique in Machine Learning.
Now we’re talking about the big stuff! A good Ensemble learning technique applied can take your models to reaches it has never seen before! (Believe me, I’ve experienced it myself.)
Ensemble learning is a technique that is used to create multiple Machine Learning models, which are then merged together to produce more accurate results. Isn’t that just great? So simple yet so powerful. A general Machine Learning model is built by using the entire training data set. However, in Ensemble Learning the training data set is split into multiple subsets, wherein each subset is used to build a separate model. After the models are trained, they are then combined to predict an outcome in such a way that the variance in the output is reduced.
Now we’re talking about the big stuff! A good Ensemble learning technique applied can take your models to reaches it has never seen before! (Believe me, I’ve experienced it myself.)
Ensemble learning is a technique that is used to create multiple Machine Learning models, which are then merged together to produce more accurate results. Isn’t that just great? So simple yet so powerful. A general Machine Learning model is built by using the entire training data set. However, in Ensemble Learning the training data set is split into multiple subsets, wherein each subset is used to build a separate model. After the models are trained, they are then combined to predict an outcome in such a way that the variance in the output is reduced.
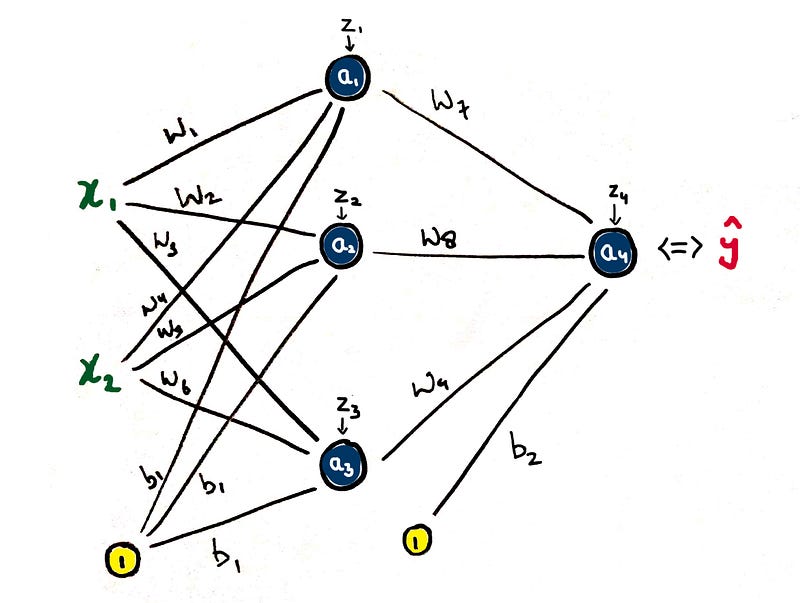
Q14. - Explain Principle Component Analysis (PCA).
Remember the ‘Curse of dimensionality’ we talked about before? Well, what can you do about it!
Remember the ‘Curse of dimensionality’ we talked about before? Well, what can you do about it!
 |
| Principal Component Analysis Example |
PCA to the rescue.
- PCA is a part of Feature Engineering wherein we try to reduce the number of features without losing the information by combining them into uncorrelated linear combinations.
- These new features (also called principal components), sequentially maximize the variance represented (i.e. the first principal component has the most variance, the second principal component has the second most, and so on).
- As a result, PCA is useful for dimensionality reduction because you can set an arbitrary variance cutoff
Q15. Explain the difference between L1 and L2 regularization.
Before that, why do we even need regularization?
“To avoid overfitting”
- How to prevent overfitting:
Both L1 and L2 regularization prevents overfitting by shrinking (imposing a penalty) on the coefficients.
- Difference between L1 and L2:
L2 (Ridge) shrinks all the coefficients by the same proportions but eliminates none, while L1 (Lasso) can shrink some coefficients to zero, performing variable selection.
- Which to use?
If all the features are correlated with the label, ridge outperforms lasso, as the coefficients are never zero in ridge. If only a subset of features are correlated with the label, lasso outperforms ridge as in the lasso model some coefficient can be shrunk to zero.
Bonus Machine learning interview questions time..!
QSuper. What’s your favorite algorithm, and can you explain it to me in less than a minute?Trust me when I say this, I’ve heard this question almost everywhere. And this my friend is not a question that I can provide you the solution with. It totally depends on your perspective and liking. The only motive of putting this question among this list of machine learning interview questions is to ask you to learn at least one algorithm in and out. It does matter if it is as simple as Linear Regression, the fact that you know it the best matters. Knowledge is essential.
(My personal favourite is Random Forest just if you wanna know!)
(My personal favourite is Random Forest just if you wanna know!)
So, these were some top Machine Learning interview questions about learning ...duh! Machine Learning obviously!
But do not limit yourself! There is a lot to learn out there. Many other important topics which I just couldn't include in my article. The possibilities are endless!
But do not limit yourself! There is a lot to learn out there. Many other important topics which I just couldn't include in my article. The possibilities are endless!
> My other blogs on Machine Learning:
> More Machine Learning Interview Questions/Resources to refer:
- Machine Learning Deep Learning Best Courses
- How to crack Data Science Interviews - Krish Naik
- Amazon Data Science Interview- Part 1 & Internship Opportunities - Krish Naik